Tentang AVX episode 1: Mengenal perbedaan sederhana set instruksi AVX, AVX2 pada CPU x86 modern
Assalamualaikum Wr. Wb. para pembaca
Yahh akhirnya udah masuk sekolah lagi huhuhuu __-""
dan sudah lama juga yak gak ngeblog karena banyak kerjaan (ehehehe ~~ )
Yak kali ini aku mo mbahas sesuatu nih ... ini kutulis waktu aku hari pertama masuk kelas 12 wkwkwkwk ... sebenarnya sih sejak lama ingin kutuliskan ... tapi sebelum itu ... perhatikan skrinsut CPU-Z dibawah ini
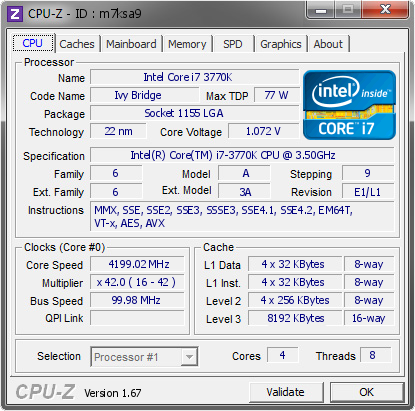
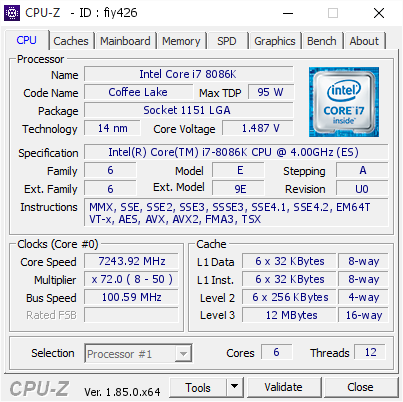
Kira kira kakak kakak tau gak perbedaan diatas ? :v banyak yaa kak ? :v banyak sekaliii ~~~ kalau persamaanya ? sama sama di Overclock :v dengan posisi All-Core ON semua :v
Gambar pertama itu CPU Intel Core i7 3770K dan yang kedua ialah CPU Intel Core i7 8086K
Jumlah core pada i7 3770K itu 4C dengan 8T (Simultaneous Multithreading) DAN Jumlah core pada i7 8086K itu 6C dengan 12T (SMT)
Generasi udah beda kakakk :v satu masih pake arsitektur Sandy Bridge dan satunya udah pake arsitektur Kaby-Lake Refresh looo kok beda ... iya soalnya Ivy Bridge itu Sandy Bridge yang dikecilin jadi 22nm sementara Coffee Lake itu Kaby Lake yang dioptimalisasi dan dikecilin pake 14nm++
dan .. Perbedaan apa lagi selain Soketnya juga beda ???? apaa yaaa ??? Perhatiin bagian Instruction nya kak ...
apa yang kakak lihat dan temuin bedanya ? satu masih pake AVX tapi satunya udah pake AVX2 dan FMA3 .. nahh itu bedanya apa yaa kira-kira ???
Oke ... aku mau jelasinnn nyuuuu~~~ >~<
Anone Anonee~~
jadi perbedaan antara AVX dan AVX2 itu terletak pada lebar jumlah register (Data Width) yang bisa ditanganin tiap pipeline nya .. kita kan tau kalau AVX itu perluasan dari jumlah register SIMD pada SSE kan ? ataupun ada juga yang bilang kalo AVX itu SSE yang dilebarkan dari 128-bit ke 256-bit kan ? (inget-inget yaa kalau MMX itu 64-bit, SSE itu 128-bit, AVX itu 256-bit dan AVX-512 itu 512-bit)
Nah ... operasi SIMD (Single-Instruction Multiple-Data) atau yang dikenal sebagai Operasi Vektor ini kan ada 2 bagian ... FP Vector (biasanya ini operasi SIMD yang terletak di Floating Point dan ditandai dengan FMUL+FADD / SSE / FMA) ataupun Integer Vector (ini operasi SIMD yang terletak di ALU (Aritmatika Logical Unit) atau Integer Vektor (VALU)) Oh iya, disini Integer itu juga bisa disebut dengan ALU (Aritmatika Logical Unit) atau Integral Data Type
Lalu .. dari penjelasan itu apa bedanya ... jelaskan yang sederhana sajaa
Oke ... perbedaanya ada di jumlah register operasi Vektor / SIMD
AVX (Advanced Vector eXtensions / Gesher New Instruction) itu memiliki jumlah register (Data Width) untuk operasi vektor (SIMD) pada Floating point itu Digandakan dari Arsitektur sebelumnya (Nehalem) yang masih menggunakan SSE (128-bit) ... karena digandakan itu tadi kak ... jumlah register (data width) operasi vektor FP pada Arsitektur setelah Nehalem yaitu Sandy Bridge memiliki jumlah register operasi SIMD Floating Point sebanyak 256-bit. maka AVX lahir karena AVX menggandakan jumlah register pada SSE yang sebelumnya dari 128-bit menjadi 256-bit dan menjadikannya lebih Advanced lagi karena adanya tambahan beberapa instruksi baru yang sebelumnya tak didukung oleh SSE. dan untuk Kompatibilitas terhadap instruksi SSE yang lawas, AVX bisa mendukung SSE dengan menggunakan VEX Prefix yang fungsinya ialah menjalankan operasi YMM pada jumlah data 128-bit kebawah

Tetapi, pada AVX, jumlah register untuk Operasi Vektor Integer masih sama seperti SSE yaitu masih 128-bit, namun meskipun demikian, AVX membawa beberapa instruksi baru yang lebih advanced daripada SSE meskipun Operasi Vektor Integer nya sama sama masih 128-bit
Sementara pada AVX2 (Haswell New Instruction) baik Jumlah Register untuk FP Vector maupun Integer Vector sudah dilebarkan ke 256-bit semua (yang artinya baik FP Vector maupun Integer Vector (VALU) sudah menggunakan lebar data (jumlah register) sebanyak 256-bit) dan pastinya membawa beberapa instruksi yang lebih baru daripada AVX.. salah satunya ialah FMA3 (3-Operand Fused Multiply Add).
FMA membawa perubahan yang signifikan karena 1 Pipeline FP-FMA dapat melakukan 2 operasi (tambah dan kali) sekaligus jadi yang dulunya untuk melakukan operasi MUL dan ADD memerlukan 2 Pipeline yaitu FMUL dan FADD, maka FMA dengan menggunakan 1 Pipeline, 2 operasi MUL+ADD dapat dioperasikan .. hal ini tentunya bisa meningkatkan operasi Single Precision maupun Double Precision pada FPU dan tentunya ini juga sangat membantu AVX/AVX2 karena dengan 1 cycle, 2 operasi dapat dijalankan sekaligus.
FMA sebenarnya lebih dulu diaplikasikan kepada CPU AMD waktu zaman Vishera (2012), dan Intel baru mengaplikasikannya di 2013 pada Haswell (bersamaan dengan AVX2).
Untuk Bulldozer, FMA yang dipakai ialah FMA4 (4-Operand Fused Multiply Add) tetapi analis mengatakan bahwa FMA3 jauh lebih baik ketimbang FMA4
Nah dibawah ini ada gambar dari beberapa EU (Execution Engine) antara Sandy Bridge (Ivy Bridge) dan Haswell


Yahh akhirnya udah masuk sekolah lagi huhuhuu __-""
dan sudah lama juga yak gak ngeblog karena banyak kerjaan (ehehehe ~~ )
Yak kali ini aku mo mbahas sesuatu nih ... ini kutulis waktu aku hari pertama masuk kelas 12 wkwkwkwk ... sebenarnya sih sejak lama ingin kutuliskan ... tapi sebelum itu ... perhatikan skrinsut CPU-Z dibawah ini
Kira kira kakak kakak tau gak perbedaan diatas ? :v banyak yaa kak ? :v banyak sekaliii ~~~ kalau persamaanya ? sama sama di Overclock :v dengan posisi All-Core ON semua :v
Gambar pertama itu CPU Intel Core i7 3770K dan yang kedua ialah CPU Intel Core i7 8086K
Jumlah core pada i7 3770K itu 4C dengan 8T (Simultaneous Multithreading) DAN Jumlah core pada i7 8086K itu 6C dengan 12T (SMT)
Generasi udah beda kakakk :v satu masih pake arsitektur Sandy Bridge dan satunya udah pake arsitektur Kaby-Lake Refresh looo kok beda ... iya soalnya Ivy Bridge itu Sandy Bridge yang dikecilin jadi 22nm sementara Coffee Lake itu Kaby Lake yang dioptimalisasi dan dikecilin pake 14nm++
dan .. Perbedaan apa lagi selain Soketnya juga beda ???? apaa yaaa ??? Perhatiin bagian Instruction nya kak ...
apa yang kakak lihat dan temuin bedanya ? satu masih pake AVX tapi satunya udah pake AVX2 dan FMA3 .. nahh itu bedanya apa yaa kira-kira ???
Oke ... aku mau jelasinnn nyuuuu~~~ >~<
Anone Anonee~~
jadi perbedaan antara AVX dan AVX2 itu terletak pada lebar jumlah register (Data Width) yang bisa ditanganin tiap pipeline nya .. kita kan tau kalau AVX itu perluasan dari jumlah register SIMD pada SSE kan ? ataupun ada juga yang bilang kalo AVX itu SSE yang dilebarkan dari 128-bit ke 256-bit kan ? (inget-inget yaa kalau MMX itu 64-bit, SSE itu 128-bit, AVX itu 256-bit dan AVX-512 itu 512-bit)
Nah ... operasi SIMD (Single-Instruction Multiple-Data) atau yang dikenal sebagai Operasi Vektor ini kan ada 2 bagian ... FP Vector (biasanya ini operasi SIMD yang terletak di Floating Point dan ditandai dengan FMUL+FADD / SSE / FMA) ataupun Integer Vector (ini operasi SIMD yang terletak di ALU (Aritmatika Logical Unit) atau Integer Vektor (VALU)) Oh iya, disini Integer itu juga bisa disebut dengan ALU (Aritmatika Logical Unit) atau Integral Data Type
Lalu .. dari penjelasan itu apa bedanya ... jelaskan yang sederhana sajaa
Oke ... perbedaanya ada di jumlah register operasi Vektor / SIMD
AVX (Advanced Vector eXtensions / Gesher New Instruction) itu memiliki jumlah register (Data Width) untuk operasi vektor (SIMD) pada Floating point itu Digandakan dari Arsitektur sebelumnya (Nehalem) yang masih menggunakan SSE (128-bit) ... karena digandakan itu tadi kak ... jumlah register (data width) operasi vektor FP pada Arsitektur setelah Nehalem yaitu Sandy Bridge memiliki jumlah register operasi SIMD Floating Point sebanyak 256-bit. maka AVX lahir karena AVX menggandakan jumlah register pada SSE yang sebelumnya dari 128-bit menjadi 256-bit dan menjadikannya lebih Advanced lagi karena adanya tambahan beberapa instruksi baru yang sebelumnya tak didukung oleh SSE. dan untuk Kompatibilitas terhadap instruksi SSE yang lawas, AVX bisa mendukung SSE dengan menggunakan VEX Prefix yang fungsinya ialah menjalankan operasi YMM pada jumlah data 128-bit kebawah

Skema Register pada SSE (XMM), AVX (YMM) dan AVX512 (ZMM)
Tetapi, pada AVX, jumlah register untuk Operasi Vektor Integer masih sama seperti SSE yaitu masih 128-bit, namun meskipun demikian, AVX membawa beberapa instruksi baru yang lebih advanced daripada SSE meskipun Operasi Vektor Integer nya sama sama masih 128-bit
Sementara pada AVX2 (Haswell New Instruction) baik Jumlah Register untuk FP Vector maupun Integer Vector sudah dilebarkan ke 256-bit semua (yang artinya baik FP Vector maupun Integer Vector (VALU) sudah menggunakan lebar data (jumlah register) sebanyak 256-bit) dan pastinya membawa beberapa instruksi yang lebih baru daripada AVX.. salah satunya ialah FMA3 (3-Operand Fused Multiply Add).
FMA membawa perubahan yang signifikan karena 1 Pipeline FP-FMA dapat melakukan 2 operasi (tambah dan kali) sekaligus jadi yang dulunya untuk melakukan operasi MUL dan ADD memerlukan 2 Pipeline yaitu FMUL dan FADD, maka FMA dengan menggunakan 1 Pipeline, 2 operasi MUL+ADD dapat dioperasikan .. hal ini tentunya bisa meningkatkan operasi Single Precision maupun Double Precision pada FPU dan tentunya ini juga sangat membantu AVX/AVX2 karena dengan 1 cycle, 2 operasi dapat dijalankan sekaligus.
FMA sebenarnya lebih dulu diaplikasikan kepada CPU AMD waktu zaman Vishera (2012), dan Intel baru mengaplikasikannya di 2013 pada Haswell (bersamaan dengan AVX2).
Untuk Bulldozer, FMA yang dipakai ialah FMA4 (4-Operand Fused Multiply Add) tetapi analis mengatakan bahwa FMA3 jauh lebih baik ketimbang FMA4
Nah dibawah ini ada gambar dari beberapa EU (Execution Engine) antara Sandy Bridge (Ivy Bridge) dan Haswell
Tuh kan kak ... terbukti kan apa yang aku jelasin tadi nyuuu .... di Sandy Bridge ... itu FP Vector dan FPU nya kan 256-bit Wide (dikatakan Wide karena jumlah pipeline nya udah fix 256-bit baik MUL dan ADD) tetapi pada Integer Vector (VMUL dan VALU nya) sama sama masih 128-bit nyuuu ~~
sedangkan di Haswell, FP Vector udah bisa operasi ganda karena adanya instruksi FMA itu tadi. sehingga beberapa orang sering bilang bahwa FP Haswell ini 2x256-bit WIDE bukan lagi 256-bit Wide. karena 2x256-bit WIDE itulah, operasi Single Precision FP atau Double Precision FP di haswell bisa meningkat 2X lipat ketimbang Haswell (Pada Sandy Bridge, kemampuan FP hanyalah 8 DP / 16 SP sementara pada Haswell (dan arsitektur berikutnya) kemampuan FP meningkat menjadi 16 DP / 32 SP
Two 4-wide FMA dan Two 8-wide FMA itu artinya
Tiap Wide untuk DP (Double Precision) ialah 64-bit dan Tiap "Wide" untuk SP (Single Precision) ialah 32-bit
jadi kalau Two-4 WIDE FMA itu artinya FPU itu dapat melaksanakan operasi sebanyak 4 buah operasi 64-bit dengan 2X operasi tiap Cycle
sedangakn kalau 4-wide AVX Addition + 4-wide AVX multiplication itu Artinya tiap FPU dapat melaksanakan operasi Penjumlahan 4 buah operasi penjumlahan (AVX) DAN 4 Buah operasi perkalian (AVX) dengan 1X operasi tiap Cycle
Oh iya catatan saja nih nyuu ... pada arsitektur Skylake-X 2 FPU ini (2x256-bit WIDE FMA) digabung (Fused) agar bisa melaksanakan operasi vektor SIMD pada FP sebanyak 512-bit (AVX512)
Kita kembali ke gambar itu nyuuu ~~ tuh kan bener kalau di Haswell baik FP Vector / FPU nya atau Integer Vector / VMUL/VALU nya itu sama sama 256-bit kan ? ARTINYA penjelasan saya tadi betulll nyuuuuu ~~ :v :V :v :v :v Holeeee ~~~~~
Nah ...sekian dulu nyuu penjelasanku hari ini ... oh iya untuk 2 postingan kedepan itu isinya ialah review salah satu pantai di gresik loo !! pantai delegan ? BUKAN ...lalu apa loo ? tunggu sajaa nyuu ~~
dan juga untuk Episode 2 aku mau njelasin tentang implementasi AVX/AVX 2 pada arsitektur AMD
melihat bahwa arsitektur AMD ini banyak sekali misteri didalamnya jadi .. tunggu sajaa yaa nyuu ~~~
Sekian dari penuliss nyuuu ~~ Wassalamualaikum Wr. Wb.
Alif Nizar Syahputra / 02 / XII-MIA 7 SMAN 1 MANYAR


Comments
Post a Comment